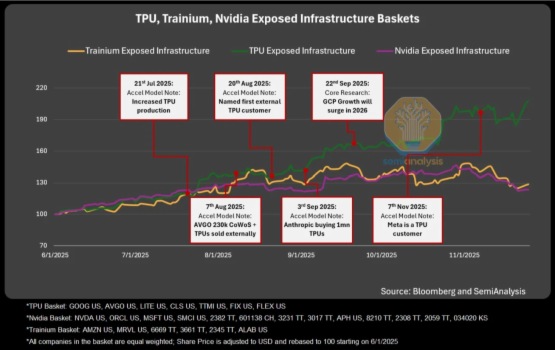
$谷歌-A(GOOGL.US) 的全栈 AI 逻辑已经演绎了一个多月,看上去围绕 OpenAI 的循环借贷故事出现破绽,从而导致 “突然” 的 AI 叙事转变。但 Google 链属于厚积薄发,技术更迭是量变引起质变,而最关键是业务定位发生了根本性的变化。
借着 Anthropic 又下 110 亿 TPU 订单,Meta 推进与 Google 底层语言开发合作之际,海豚君来梳理一下:
1)TPU 生态到底发生了什么关键变化?
2)如何厘清 Google 与 Anthropic、Broadcom 之间的订单关系?
3)当下估值打入了多少 TPU 预期?

一、直击核心问题:TPU 的积存订单与增量收入确认
1、TPU 的技术替代 “突然” 爆发?
如果不是在行业内,这可能大家的第一个疑问。在市场大多数记忆还停留在 TPU 通用性不够,Google 主要用来内用而非对外商用上时,会非常讶异为何到了 TPU v7 这一版本,突然开讲 TPU 对的 GPU 替代逻辑。
这并非市场的重大忽视,奇点形成的关键是 TPU 在集团内部的战略定位转变——从 “对内为主” 转为 “对外直接商用”,促使在芯片设计理念上发生了根本性的变化。
在这一轮 AI LLM 时代之前,TPU 的设计理念都偏保守。与英伟达 idia 在设计上更偏重单片核心算力的持续升级,TPU 在设计上更聚焦性价比,即以牺牲极致单片性能,而避免故障率走高导致的物理磨损加速、元件老化、散热压力等问题的出现,从而拉高了整体成本。
当然这么设计的原因还在于,在 TPU 对内使用下对性能追求点与 LLM 也存在差异,尤其是在算力指标上。一方面内部的广告推荐模型不需要这么高的算力吞吐,另一方面没有商用压力,自然也就没有 “炫技” 的必要性。
比如下图比较了广告推荐模型(Reco)和 LLM 大模型对硬件的性能不同需求,在 Reco 模型下,对算力吞吐、网络延迟上的要求没 LLM 那么高。

但随着 LLM 时代到来,算力要求大幅提高,集团在对 TPU 的设计思路本身需要升级改变。这个时候顺便对 TPU 开启直接商用,还能在当下的千亿算力市场分一杯羹,何乐而不为?于是我们看到,2024 年中推出的 TPU v5 版本在单片算力上出现了显著提升,并在随后的 v6、v7 版本继续大幅拉高。
而在 LLM 另外需要的存储性能——内存带宽、内存容量上,TPU v7 版本直接拉齐到了 GB200 的水平,但单卡性能与 GB300 以及英伟达的 Rubin 系列还有明显差距。
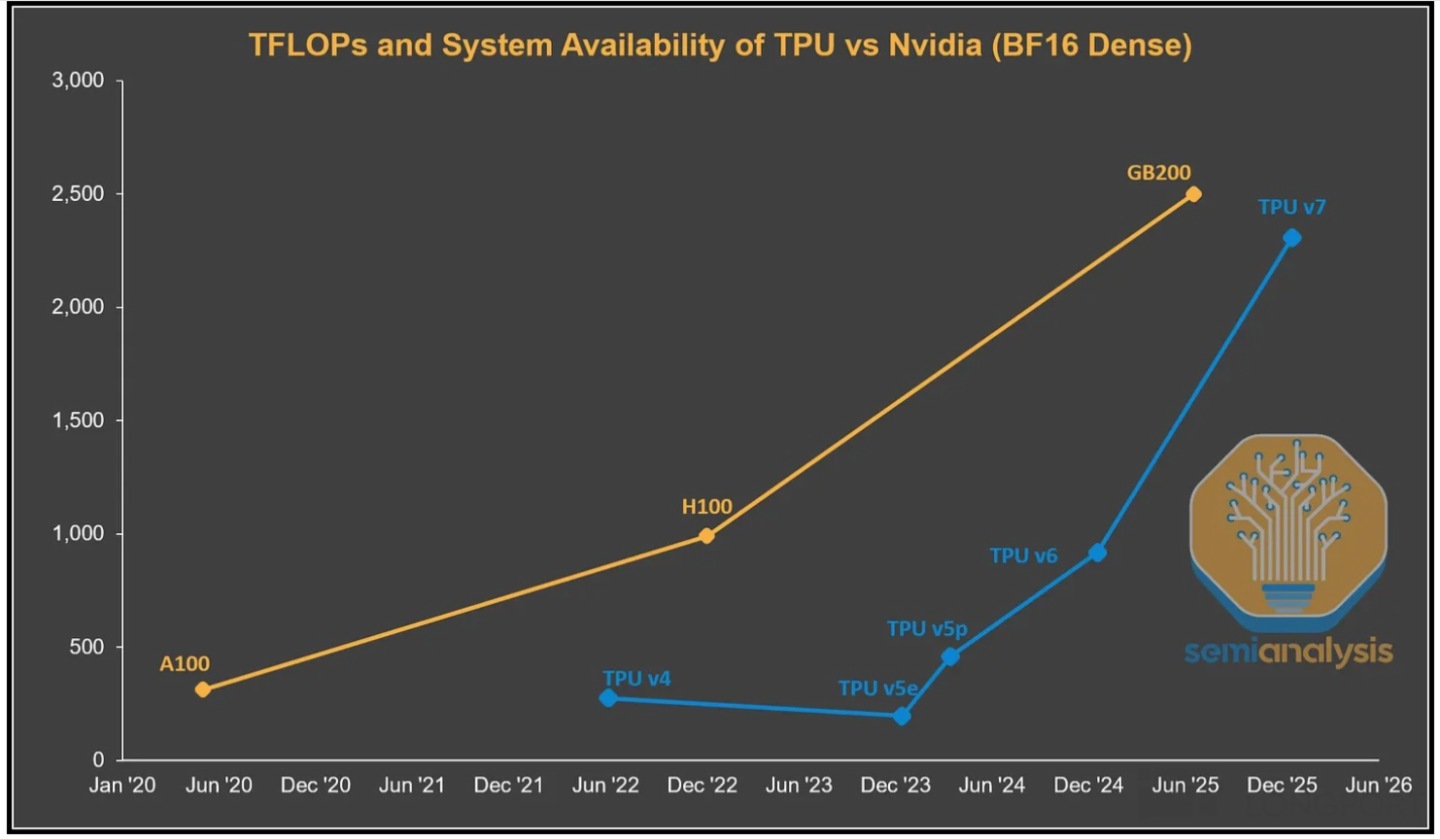

2、大厂客户 “突然” 密集下订单?
9 月被爆、10 月正式官方披露的 Anthropic 百万颗 TPU 订单可以说是一石激起千层浪,TPU 真正走到舞台中央。依据专家调研信息,预计 2026 年 TPU 出货量将达到 300 万颗,在 2025 年的低基数上增幅达到 66%。

但前几天博通的 Q4 业绩发布,提到了 Anthropic 新下的一份 110 亿 TPU v7 订单,预计 2026 年底交付,按单价来算,那么也是对应 40-50 万颗的 TPU v7。因此如果能够按计划实现交付,那么 2026 年 TPU 出货量将至少达到 350 万颗数量级。
下图为 Anthropic 的两次订单情况,爆出在接触合作的 Meta、OpenAI 等具体细节还未确认:

不过,虽然纸面上的技术替代性实现了,但要真正获得头部大客户的青睐还需要依赖三个关键因素,1)性价比;2)芯片封装产能配给;3)开发生态,实际对应 1)有效算力成本;2)台积电的 CoWoS 产能;3)开发者生态,一如英伟达 idia 核心壁垒——CUDA 生态。
(1)以量取胜,不做铲子商
虽然 TPU v7 在单卡 Raw Power(原始算力)上可能略逊于英伟达 idia B200,显著逊于 B300、R100。但在万卡集群的有效算力(MFU)上,Google 凭借独家的 OCS(光路交换)互联技术,能大幅缓解传统 GPU 集群随着规模扩大而损耗指数级上升的 BUG。
正如前文所说,单卡极致性能会导致整体硬件的故障率走高,产生磨损、老化、散热等问题,算力使用效率反而一般,后续的维护会带来更高的成本压力。
简单而言,Anthropic 看中的是性价比,即 “1 美元部署对应的算力”。如下图所示,TPU v7 单位算力价格(运行一颗芯片 1 小时,所需要的综合成本,包含芯片和数据中心基建成本、电力成本、维护人力成本等)便宜了近 44%,且其中一次性投入的硬件和基建成本(对应客户的 Capex,需要前置投入)占比在 72.7%,也比 GB 系列的 77%~79% 略低时,TPU 无疑会进入下游客户算力方案选择的最终 “决赛圈”。


(2)改变信披战术,锁订单抢产能
尽管台积电和英伟达多年深度合作,且在过去一年多的算力军备竞赛上,双方携手获得了产业链中绝大部分的利益,但这层关系并非绝对捆绑到无懈可击,尤其是当市场开始质疑 OpenAI 的变现力,以及与英伟达之间循环贷款对订单的增长持续性。从风险规避的角度,台积电会更加注重客户是否存在 “有交付能力的在手订单”,从而决定产能配给。
因此 Google 对 TPU 的信息披露也对应着发生了变化。既然要与英伟达 idia 竞争,那么也就是需要和英伟达一样,尽早公布新产品路线,以便成为客户做未来算力规划时的待选方案之一。通过提前锁定订单,从而能从台积电处拿到产能。
TPU v7 之前,Google 对 TPU 的信息披露会更加谨慎,毕竟被认定为只对内的 “秘密武器”。比如,2015 年 TPU 一代就已经落地并且被 Google 进行大规模的部署和使用,但直到 2016 年 Google I/O 大会才对外公布它的存在。随后的 2-6 代,虽然披露略有放宽,一般是 I/O 大会发布 PPT 后一年内就实现了 Cloud 上线使用,也就是说在发布时就已经谈好了产能规划。
但这次 v7,为了抢到订单,Google 早早发布 TPU v7 产品细节(2025 年 4 月发布),但彼时产能还未锁定,直到 8 月盛传 Broadcom 追加对 CoWoS 的产能(大概率是因为为 TPU v7 提前准备),随后 9 月 Anthropic 才敲定与 Google TPU 的合作,涉及到 TPU 机架的直接销售(10 月底公开披露),而最近当 Anthropic 追加了 110 亿订单,Broadcom 则再次与 TSMC 锁定明年的产能。
因此,从 Broadcom 向 Anthropic(最早下订单的头部客户)允诺的交付时点来看(2026 年中和 2026 年底),Google 对 TPU v7 的信息披露要相当于早于实际部署的 1-2 年的时间,明显早于前几代。
(3)为何说英伟达的软件生态优势出现裂缝?
但能让动不动砸上百亿支出的大厂们,敢于下 TPU 的订单,光靠便宜肯定不够,关键在于软件生态的有效完善,这也是 TPU 走向大规模商用需要解决的关键问题。
英伟达之所以壁垒深厚,硬件单卡性能只是表面,CUDA 才是里子。CUDA 是英伟达 idia 推出用来让 GPU 理解 C+、Python 的底层算子库,近 20 年行业的开发经验积累,使得 CUDA 在 AI 开发领域几乎不可跨越:前一代的工程师们基于 CUDA 写好了工具模块 PyTorch,后一代的工程师们无需从 0-1 写代码,而是直接套用 PyTorch 工具来做进一步的开发。
由此看来,要颠覆 CUDA,最重要的是 “工具库” 和 “人才”。那么 TPU 是怎么解决的呢?
a. 主动的定点优化:编译器 2.0+vLLM 直接支持 TPU
对应 CUDA,TPU 的底层算子库是 Pallas。由于 TPU 发展晚一些,且之前一直对内,未对外商用,因此 Pallas 生态里面几乎只有 Google 自己的工程师在补充算子。而 TPU 生态中与 PyTorch 工具库对应的,则是 JAX。由于手写 Pallas 算子的过程太复杂,Google 另外推出了 XLA 编译器,来实现从 JAX 到底层指令集(TPU Runtime)的调用。

但一己之力 vs 多人合力的天然弱势,要让 Pallas/JAX 去追赶 CUDA/PyTorch 的难度太大。软件生态的缺陷成为 TPU 商业化的核心阻力之一,除非客户本身具备 JAX 人才(这几乎只有 Google 内部的人跳到甲方关键岗位,再身体力行的推行 JAX 才行)。
因此 Google 推出了 PyTorch/XLA 编译器,它能让原本为 GPU 设计的 PyTorch 代码,编译并运行在 TPU 上。1.0 版本还不太丝滑,但 23 年推出的 2.0 版本,优化了 1.0 版本的 TPU 启动速度慢问题,不过还是会出现首次编译时间长等问题。
又一个转折点在 2024 年下半年,Google 实现了 vLLM 对 TPU 的原生支持——2024 年 7 月底披露,vLLM 可以实现在 TPU v5e 和 v6e 上运行,随后不断完善。
vLLM 是目前 AI 推理(让模型回答问题)领域渗透率最高的开源软件库,最早是为了解决英伟达 idia 显卡碎片化问题而诞生,因此天然适配 GPU。Google 为了让 vLLM 实现对 TPU 的原生运行,与 vLLM 团队深入合作,使用 Pallas 重写了基于 vLLM 的核心算子,通过使用 JAX + Pallas,vLLM 可以直接调用 TPU 的底层内存管理能力,避开了 PyTorch/XLA 编译器带来的延迟和额外开销。
c. 被动的开发者渗透:“AI 黄埔军校” 的人才战术
这一轮 AI 基建,上游厂商吃了产业链绝大多数利润,但行业的繁荣最终来自下游的百花齐放。对于上游而言,捆绑客户以获得持续的需求是关键。英伟达 idia 采取的方式是股权投资,相当于 “芯片折扣 + 风险投资收益”。
做股权捆绑并没有壁垒,都是送钱,Google 完全可以复制操作。实际上,Google 很早就对 Anthropic 进行了积极投资,投入 30 亿持股比例达到 14%(不含投票权)。目前 Anthropic 估值达到近 2000 亿美元,且不论是否捆绑芯片合同,Google 已经从这笔风投中获得了不错的收益。
但还是那句话,单纯股权捆绑(“送钱”)并不是独家方案。CUDA 的繁荣也在于生态强大,也就是开发者众多。因此,这里面的关键因素还是 “人才”。
上文提到 vLLM 直接支持 TPU,这对头部客户来说是明显利好。毕竟这个路线绕开了编译器,如果要实现丝滑运用,那么还要配备足够懂 JAX/XLA 的 TPU 人才,对于头部用户,Google 应该会专门配备技术支持团队。
但实际上还有 “意外之喜”,作为 AI 老牌大厂的 Google,这么多年同时也在对外 “输送” 人才。因此,Anthropic 的 100 万 TPU 大单能够促成,少不了 “人” 的推动——Anthropic 内部有不少前 DeepMind 的 TPU 人才,因此在这次合作之前,内部就已经在 TPU 上训练了 Sonnet 和 Opus 4.5。
因此从上述的 “技术迭代 + 人才推动” 两个角度而言,TPU 的软件生态问题可以比预想的速度更快实现补漏。
二、新一轮 AI 叙事下 Google 的价值
全栈 AI 的叙事逻辑在资本已经演绎了两个月,Google 在此期间也上涨了近 30%,成为 2025 年初绝对想不到的 Mag 7 明星。虽然近期 Google 也跟随 AI 情绪转冷而暂停了上涨趋势,但不可否认,在当下 Google 的 AI 逻辑仍然是相对较顺的。
因此在这个 “中场休息” 时段,海豚君来扒扒账:若 2026 年 TPU 也走到 AI 算力的聚光灯下,那么对 Google 的价值会有多少增量?近 4 万亿美金市值的 Google,打入了多少 TPU 预期?
1. Google 版的算力是如何赚钱的?
在今年 Q2 之前,Google 主要通过 GCP 做算力租赁的服务,出租的算力有英伟达 idia 的 GPU 也有自己的 TPU。但从 Q2 推出 TPU v7 开始,正式开启 TPU 芯片直销的大规模商用。
不同服务的提供,对应不同的利润率,同时也代表 Google 背后的战略意图:

(1)GPU 算力租赁:属于 GCP 云业务;本质上是英伟达 idia 的二道贩子,自然毛利率最低只有 50% 左右,主要给那些技术能力较弱的中小厂商准备(不愿意用 TPU 编译器把基于 CUDA 写的底层代码重写一遍),承接一些外溢的算力需求。
(2)TPU 算力租赁:属于 GCP 云业务;因为 TPU 自研,因此少了中间商赚差价,再加上本身技术路线的差异,尽管 TPU 算力租赁价格是 GPU 的 60%-70%,但对于 Google 来说,仍然可以赚 70-80% 的毛利率。
(3)TPU 机架销售:属于第三方的算力售卖服务,等于是和英伟达等同台竞争。TPU 并非像 GPU 那样 “即插即用”,TPU 的优势是 ICI(芯片间互连)和 OCS(光交换),单台服务器无法连入超高速的光网络,因此最小销售单位是一个服务器机架,每个机架包含 64 颗 TPU 芯片。
具体销售时分成两种情况:
一种是 Broadcom 直销客户,Google 收个 GDC 软件栈的技术支持费;
另一种是 Google 直销客户,那么 Google 确认硬件收入,Google 付给 Broadcom、SK 等的硬件采购、代工费用为成本。
由于 TPU 需要客户具备一定的技术适配能力,因此客户目前都是行业头部。Anthropic 是由 Broadcom 直接发给 Anthropic,但 Meta、xAI 等目前正在排队与 Google 商量 TPU 合作事宜等,也不排除是上述后者情况。
在 Anthropic 的合作案例里面,由于是 Broadcom 直销 + 托管 Anthropic 自己找的第三方数据中心,因此这里面 Google 并不确认硬件销售收入,只是对 Anthropic 使用 TPU 软件栈(系统软件、编译器 XLA 和框架 JAX)收取一定的技术支持、安全更新的服务费。
这部分主要是研发前置投入、人员团队的支持,所以边际成本较低,对 Google 来说,毛利率可以做到很高。
这里面的特殊之处在于,在 Anthropic 预定的近 100 万块 TPU 上(第一笔 40 万块 + 第二笔 40-50 万块),Google 并未染指 TPU 硬件收入部分。海豚君认为,至少在与英伟达 idia 合作密切的头部厂商上,Google 还是更倾向于不赚所谓的 “铲子钱”。
这是因为,英伟达 idia 及其生态伙伴对 Anthropic 等头部客户都用股权投资来给了个内部折扣价:
a. 英伟达投资 OpenAI 1000 亿,以换取 10GW 算力合同的绑定,暂时不看股权增值收益,相当于给 OpenAI 打了个七折(1-100/350);
b. 微软、英伟达分别向 Anthropic 投资 50、100 亿,换取 300 亿的 Azure 合同,相当于打了个对折。
因此这种情况下,如果单颗系统级 TPU v7 价格再算上 Google 的溢价,那么就相对 H200、B200 没有明显的性价比优势了。
可以合理推测,Google 并未参与到 TPU 硬件销售收入的分成上,而目的是做大 TPU 生态(尤其是开发者生态),后续通过按年付费的软件栈服务,以及云租赁算力来获得更多具备一定溢价的变现。
当然,这也不排除如果 TPU 生态完善度提升,Google 也可以做起芯片直销的模式。但短中期而言,我们认为还是做大生态、让更多的开发者参与进来是主要目标,卖铲子(实际也卖不出太多溢价)只占少数。
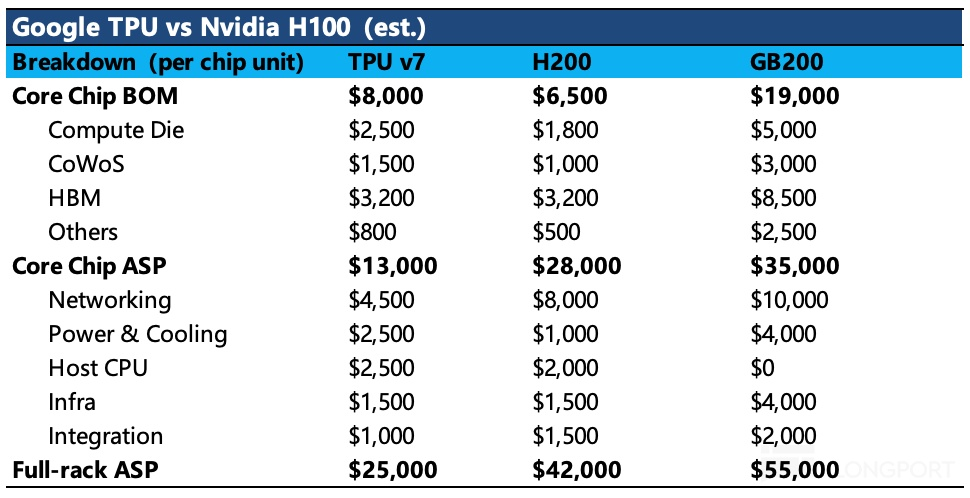
2. 当下估值隐含了 TPU 多少预期?
从积压合同额(Revenue Backlog)来看,Google Cloud 最早在 2024 年二季度就已经受益 AI(收入反映在 3Q25)。不过彼时 Google Cloud 的客户大多还是以中小企业、传统企业的需求为主,除了 Workspace 的惯性增长趋势,在 AI 方面贡献增量(数十亿量级)的产品形式还主要是 Gemini 大模型的 API。
而在芯片算力上,Google 还在遵循市场主要方案,按部就班的采购英伟达芯片——2025 年初采购 Blackwell 系列(GB200、300)。
2025 年二季度,随着 TPU v7 的发布以及市场对 AI 的使用渗透升级,积压合同余额在高基数上重新加速增长,这里面应该就已经有了一些 TPU v7 带来的算力租赁增量。
而三季度净增的 470 亿中,应该就包含 420 亿的 Anthropic 算力租赁订单(前文 Anthropic 订单明细表格中 60 万颗 TPU 算力租赁,按照每颗 TPU v7 1.6 美元/小时单价计算,60 万 *1.6 美元/h*24h*365 天 *5 年=420 亿美元)。
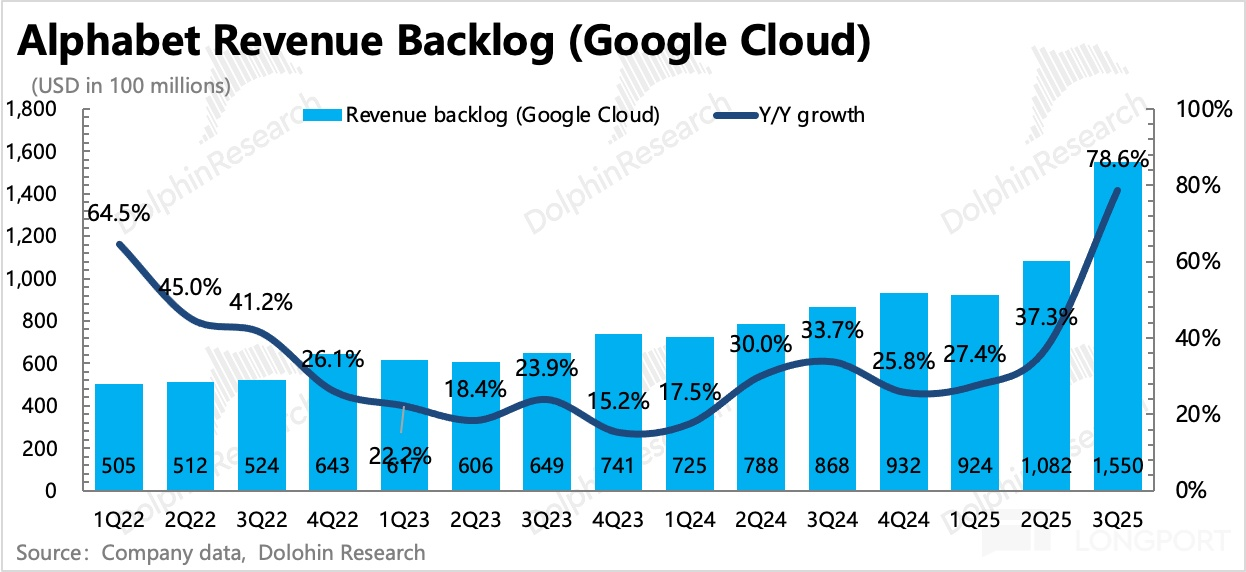
Anthropic 并非刚开始租 TPU 算力,而是一直在用,只不过过去占比不高而已。这次 420 亿的算力租赁订单,5 年周期下平均每年将带来 84 亿的 Google Cloud 收入,这相当于 2025 年预计 615 亿美元 Google cloud 收入的 14%。
目前在 TPU 算力租赁这块,大厂里面还有 Apple,中小厂比如 Snap,传统 SaaS 的 Salesforce 以及 AI 新贵 Midjourney。Meta 在 11 月也已经宣布有意合作:
第一阶段(2026 年)为算力云租赁,第二阶段(2027 年)为 TPU 直采,然后部署在自己的数据中心。近日被爆料进展,双方就底层语言的畅通正在共同开发 TorchTPU,一如其名,旨在将 Meta 基于 Pytorch 写的代码,能够更加丝滑的运行在 TPU 上。
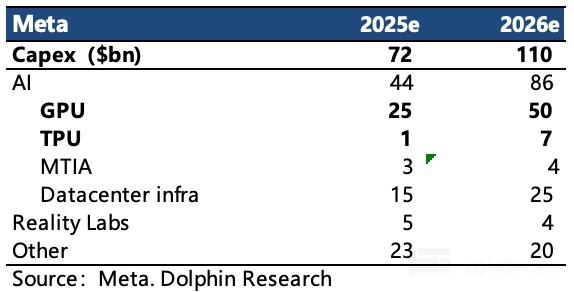
根据机构原来预期,Meta 2026 年 Capex 为 1000-1200 亿,近期 Meta 有意收缩元宇宙投入(约减少 30%)。GPU 原计划采购 100 万颗,大头为 GB200,另外为 V100。
但现在,考虑到 Meta 目前正在积极接触 Google TPU,海豚君预计 TPU 合同为 70 亿,但 2026 年主要还是算力租赁,这部分支出计入 Meta 的 Opex,芯片采购部分为 20 亿。剩下 500 亿美元为 Blackwell 系列采购额,在一定折扣下,有望获得对应 2GW 的算力,如下图预估:
如果 20 亿芯片采购合同,直接与 Google 交易,按照 2.5 万美元/颗,对应 8 万颗。2027 年预计该芯片采购升至 50 万颗,那么直接带来 50*2.5 万/颗=125 亿合同额(如果直接从 Broadcom 拿货,那 Google 不确认硬件收入),按照 3~5 年,平均 5 年的使用周期来算,每年确认收入 25 亿。
这部分 TPU 对应算力规模大约 0.5GW,如果 Meta 目标算力需求不变,那么相当于 175 亿的 GPU 收入被影响了。总而言之,无论采取什么样的 TPU 交付方式,或者对 Google 的收入有主要拉动,对利润是次要拉动,但对英伟达 idia 收入预期的影响会因为同等算力下英伟达 idia 溢价更高而同步放大。就如上文,TPU 拿了 125 亿的合同,单英伟达产生了近 175 亿的收入缺口需要从别处找补。
回到 Google 身上,由于 TorchTPU 的开发进展并不确定,因此我们暂时将 Meta 的 TPU 订单视为乐观预期下的向上期权。即中性预期下,仅考虑 Anthropic 这一个头部客户:
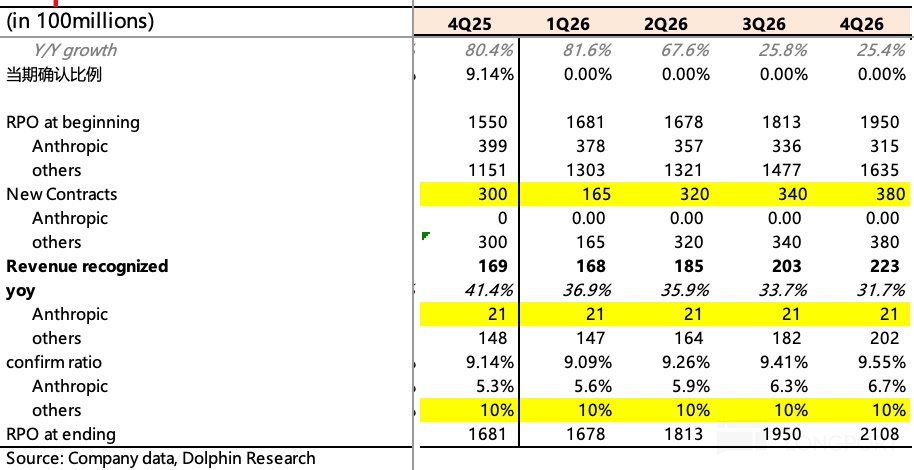
按照我们假设,2026 年预计 Google Cloud 收入为 787 亿,同比增幅 34%,其他的 Google Services 收入预期增长 10% 保持不变。当前 3.65 万亿美金,剔除掉 Services 部分估值(经营利润预计为 1520 亿,利润率 39%,PE 给到 15x),那么 Google Cloud 市值 1.32 万亿对应 17x EV/Sales。
和同行比,谷歌云业务估值并不算低,说明至少是租赁 TPU 算力上,中性预期的估值打入得差不多。要进一步消化估值办法就是等到 Meta 的订单(26 年算力租赁,或者是 27 年 TPU 由 Google 直销,如统一按照 15x EV/sales 对应 26 年估值新增 1050 亿美元,相比当前还有 3% 左右的空间提升),或者是中小公司比我们的预期更好。
因此换句话说,每一次与 Meta 的合作进展披露,都有可能对短期 Google 股价带来提振。若最终合同额不足我们预期的 70 亿,那么短中期的提振效果会相对有限。尤其是预期拉得过高的时候,还要考虑 26 年拥有接近 10 亿 MAU 的 OpenAI 如果加速变现可能给谷歌带来的向下风险。
但从另一个角度,若 Google 以牺牲短期业绩的代价,换来了更广的 TPU 渗透——比如继续压价,或者从 Broadcom 直销客户,虽然没有吃到太多硬件直销收入,但是让更多的客户开始适应 TPU 的底层框架,后续仍可通过软件栈、云租赁的形式收回来,这与 GPU 在硬件销售时表现出的高额英伟达税,本质是一样的,都是一种竞争垄断的溢价。
<此处结束>
海豚研究「Google」相关文章:
财报季
2025 年 10 月 30 日电话会《谷歌(纪要):我们是唯一一家全栈 AI 的云平台》
2025 年 10 月 30 日财报点评《谷歌的神反转:从 AI“牺牲品” 变 AI“弄潮人”》
2025 年 10 月 30 日电话会《谷歌(纪要):云业务大单翻倍,算力紧缺还会延续到明年》
2025 年 10 月 30 日财报点评《谷歌: AI 狼没来,广告一哥稳坐钓鱼台》
2025 年 4 月 24 日电话会《Google(纪要):定调二季度表现还为时尚早》
2025 年 4 月 24 日财报点评《谷歌:关税大棒挥不停,广告一哥真能稳如山?》
2025 年 2 月 5 日电话会《谷歌(纪要):云放缓是投入不够,后面还要投投投!》
2025 年 2 月 5 日财报点评《谷歌:750 亿狂砸 AI,大哥疯起来超 Meta》
热点
2025 年 10 月 27 日《谷歌:我命由我不由 OpenAI》
深度
2023 年 12 月 20 日《谷歌:Gemini 解不了 “小鬼” 缠身,明年日子不容易》
2023 年 6 月 14 日《深度长文:ChatGPT 是劫杀谷歌的 “灭霸响指”?》
2023 年 2 月 21 日《美股广告:TikTok 之后,ChatGPT 要掀起新 “革命”?》
2022 年 7 月 1 日《TikTok 要教 “大哥们” 做事,Google、Meta 要变天》
2022 年 2 月 17 日《互联网广告综述——Google:坐观风云起》
2021 年 2 月 22 日《海豚投研|细拆谷歌:广告龙头的修复行情结束了吗?》
2021 年 11 月 23 日《Google:业绩与股价齐飞,强势修复是今年主旋律》
本文的风险披露与声明:海豚投研免责声明及一般披露
内容来源:长桥海豚投研